The TeamForge Orchestrate architecture aims for extensibility, fault tolerance, and scalability.
Overview
End users experience TeamForge Orchestrate as a seamless component of TeamForge. However, under the covers Orchestrate is a separate application with a distinct architecture. This article intends to give an overview of that architecture to assist with installation and administration of the underlying services as well as an overview of the message queue (MQ) architecture used to integrate with and collect data from external sources.
Architectural Components
- Orchestrate application server: Orchestrate is a Ruby on Rails application that runs on the Phusion Passenger application server with Nginx as a web server. The application server also hosts a number of daemons that read messages from RabbitMQ.
- MongoDB: Orchestrate persists end user-facing data to MongoDB, a NoSQL variety document-store database.
- RabbitMQ: Orchestrate relies on a message queue architecture to integrate with external sources. RabbitMQ is used to collect activity data from sources like work item, SCM, build, and code review systems.
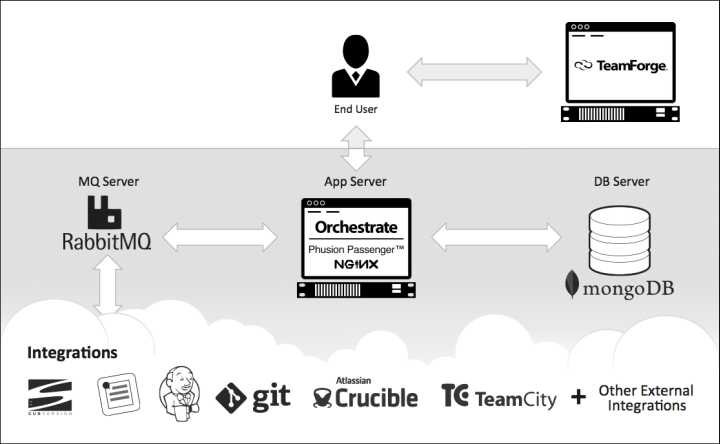
Hosting Considerations
TeamForge Orchestrate is designed for host separation, where each component resides on different operation systems. Any component may be run on virtualized hardware. In the absence of separate hardware or virtualization, Orchestrate components may be collocated. Resource requirements for components are documented in the Installation section.
Load balancing and clustering
TeamForge Orchestrate components may be load balanced and/or clustered. The Orchestrate application server may be installed on multiple hosts and load balanced (session clustering is not required). MongoDB and RabbitMQ both support clustered modes as well. However, such configurations are not documented or supported and are only offered as supplemental services from CollabNet.
Integration with external sources
TeamForge Orchestrate uses a MQ architecture to collect data from external sources like work item, SCM, build/CI, and code review systems. The diagram below demonstrates a clustered network of MQ servers that share data collected from external sources. When a relevant activity occurs, the external source uses an MQ agent to publish a specially formatted message to the MQ network. MQ servers can be clustered and strategically located to prevent loss of messages during to outages.
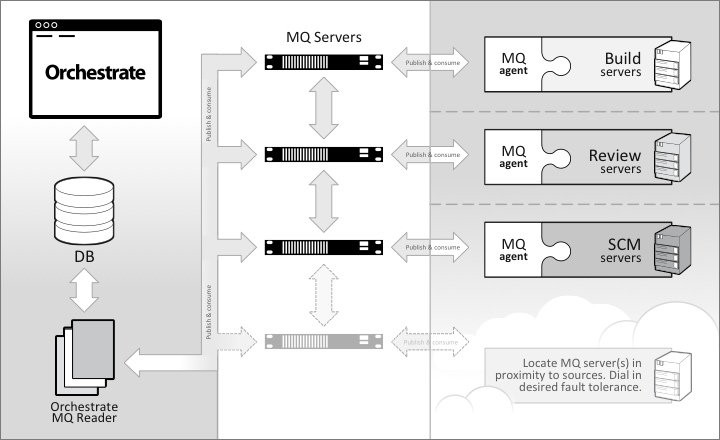
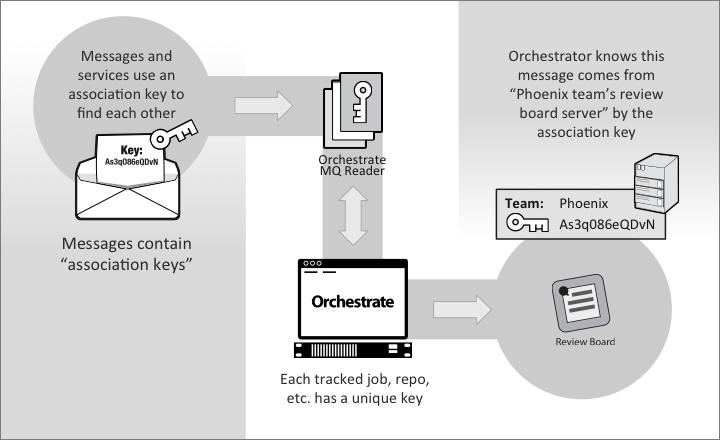
Once a message is published by an external source, it is consumed by a daemon service running on the Orchestrate application server. The message is parsed and the data is persisted. MQ adapters are configured with "association keys": unique identifiers that enable Orchestrate to file incoming data into the appropriate source.
Extensibility
Orchestrate ships with a handful of packaged adapters to common work item, SCM, build/CI, and review systems. But what if you are using different tools in your process? You can integrate your tools by building adapters that work by publishing MQ messages that are consumed by Orchestrate. See the Extensibility documentation for more on writing TeamForge Orchestrate adapters: Extending TeamForge Orchestrate.